
环境准备
我这里环境基于
Hadoop环境搭建 MapReduce环境搭建 Hive环境搭建虚拟机配置也均基于上述环境
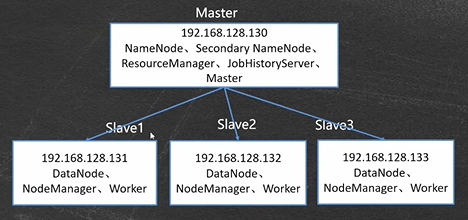
Spark集群搭建完毕之后,集群拓扑如下
Spark下载
进入官网下载页面,选择一个版本下载
我这里下载的版本是
spark-3.2.1-bin-without-hadoop.tgz
解压安装包
1 | tar -zxvf spark-3.2.1-bin-without-hadoop.tgz |
配置Spark
进入spark安装目录的conf文件夹下
配置workers
注意在spark 3.x以前版本是slaves文件,现在最新的3.x版本为workers文件
复制workers cp workers.template workers
修改workersvim workers
删除localhost添加如下内容
1 | node1 |
配置spark-defaults.conf
复制配置文件cp spark-defaults.conf.template spark-defaults.conf
编辑配置文件vim spark-defaults.conf
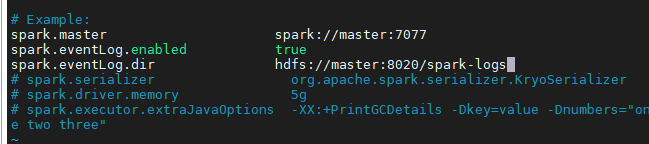
可以看到这里的example

我们取消部分注释并修改如下
配置spark-env.sh
复制配置文件
cp spark-env.sh.template spark-env.sh
编辑配置文件
vim spark-env.sh
加入以下内容
1 | JAVA_HOME=/usr/java/jdk1.8.0_202-amd64 |
启动Hadoop集群,创建spark-logs目录
hdfs dfs -mkdir /spark-logs
分发到各节点
1 | scp -r /opt/spark-3.2.1-bin-without-hadoop node1:/opt/spark-3.2.1-bin-without-hadoop |
配置环境变量
1 | export SPARK_HOME=/opt/spark-3.2.1-bin-without-hadoop |
启动spark集群
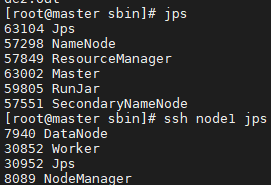
进入spark安装目录的sbin中,使用命令./start-all.sh即可启动spark所有节点
踩坑
1 | Error: A JNI error has occurred, please check your installation and try again |
因为我们下载的是without hadoop版本,所以需要手动指明本地的hadoopde 的classpath路径
在spark-env.sh中追加一行
SPARK_DIST_CLASSPATH=$(/opt/hadoop-3.1.4/bin/hadoop classpath)
将配置变更传送到各个节点
1 | scp spark-env.sh node1:/opt/spark-3.2.1-bin-without-hadoop/conf/spark-env.sh |
参考文章: 【spark】spark-2.4.4的安装与测试 (lagou.com)
启动spark日志服务
在安装目录的sbin文件夹下
使用./start-history-server.sh启动
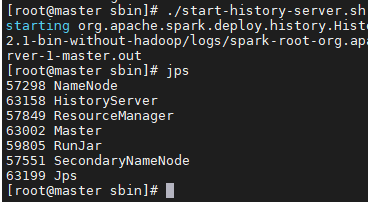
打开浏览器监控
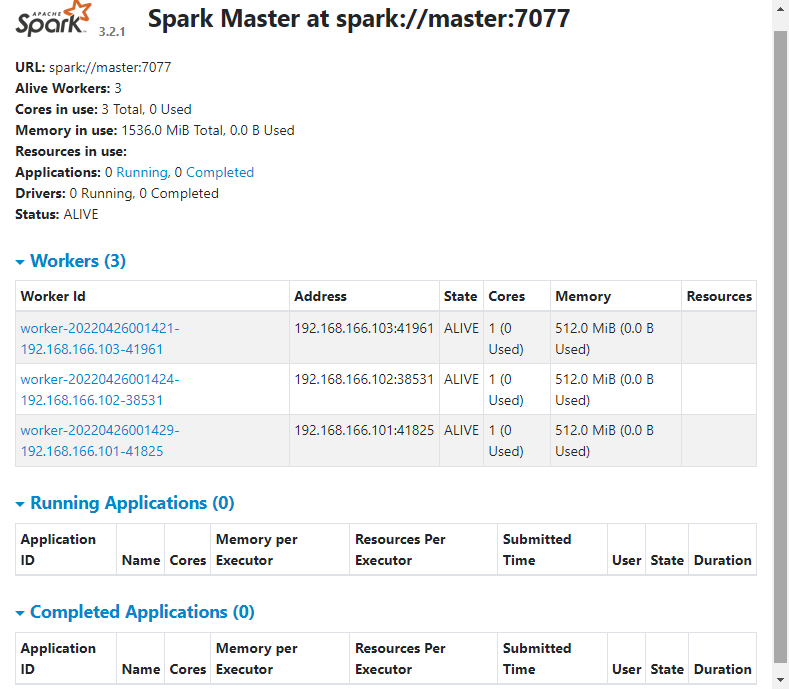
通过访问master的8080端口,打开浏览器的监控页面
http://192.168.166.100:8080
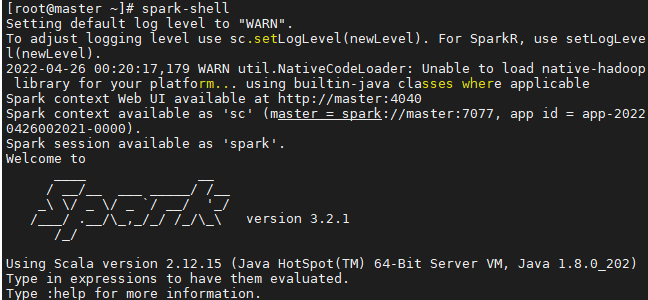
启动spark-shell
 wechat
wechat- alipay

