需求分析
实现给定一个文件,统计其中单词出现的数目。
准备工作
新建文件test.txt如下
1 | I am a student |
上传到hdfs上
hadoop fs -put test.txt /user/wordcount.txt

Spark shell
输入如下命令,即可实现词频统计
1 | sc.textFile("/user/wordcount.txt") |
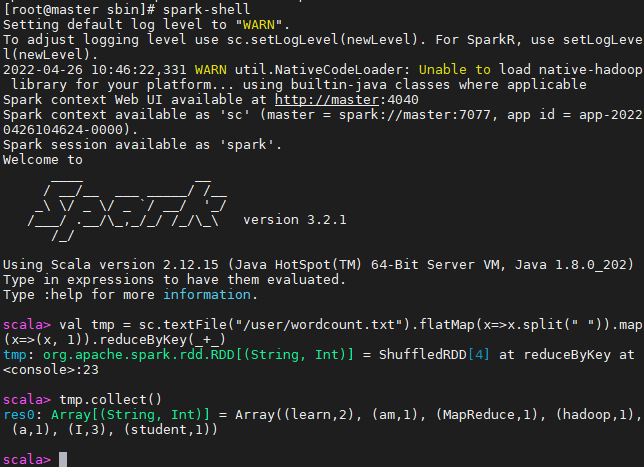
踩坑
我这里出现了如下提示,并且计算停滞不前
1 | 2022-04-26 00:36:13,830 WARN scheduler.TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources |
估计是资源不足,修改spark-default.conf配置文件,增大内存后,正常运行。
Pyspark
通过pyspark shell
输入pyspark启动python的shell
1 | sc.textFile("/user/wordcount.txt")\ |
可以看出几乎与原生的基于scala的shell没多大区别
运行结果如下

踩坑
需要预先安装好所有节点的python3
1 | yum install python3 -y |
通过py文件
编写my.py文件如下
1 | from pyspark.sql import SparkSession |
使用spark-submit my.py提交任务
输出结果如下
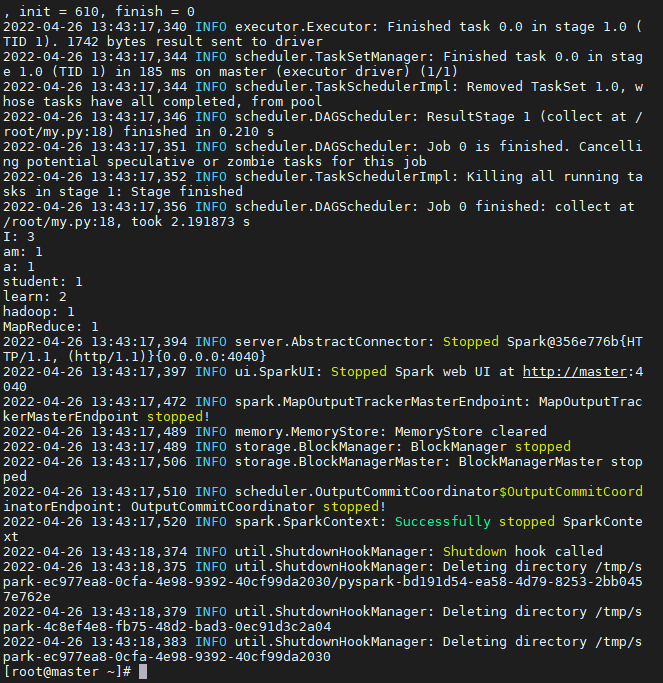
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Zhangzqs!
 wechat
wechat- alipay


评论