
大数据概述
概念
BigData, 指无法在一定时间范围内用常规工具软件进行捕捉、管理和处理的数据的集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力来适应海量、高增长率和多样化的信息资产。
特性
6V特征
-
价值密度低(Value)
-
高速性(Velocity)
-
可变性(Variability)
-
海量性(Volume)
-
多样性(Variety)
-
真实性(Veracity)
关键技术
大数据的采集、导入/预处理、统计/分析、大数据挖掘
与云计算,物联网的关系
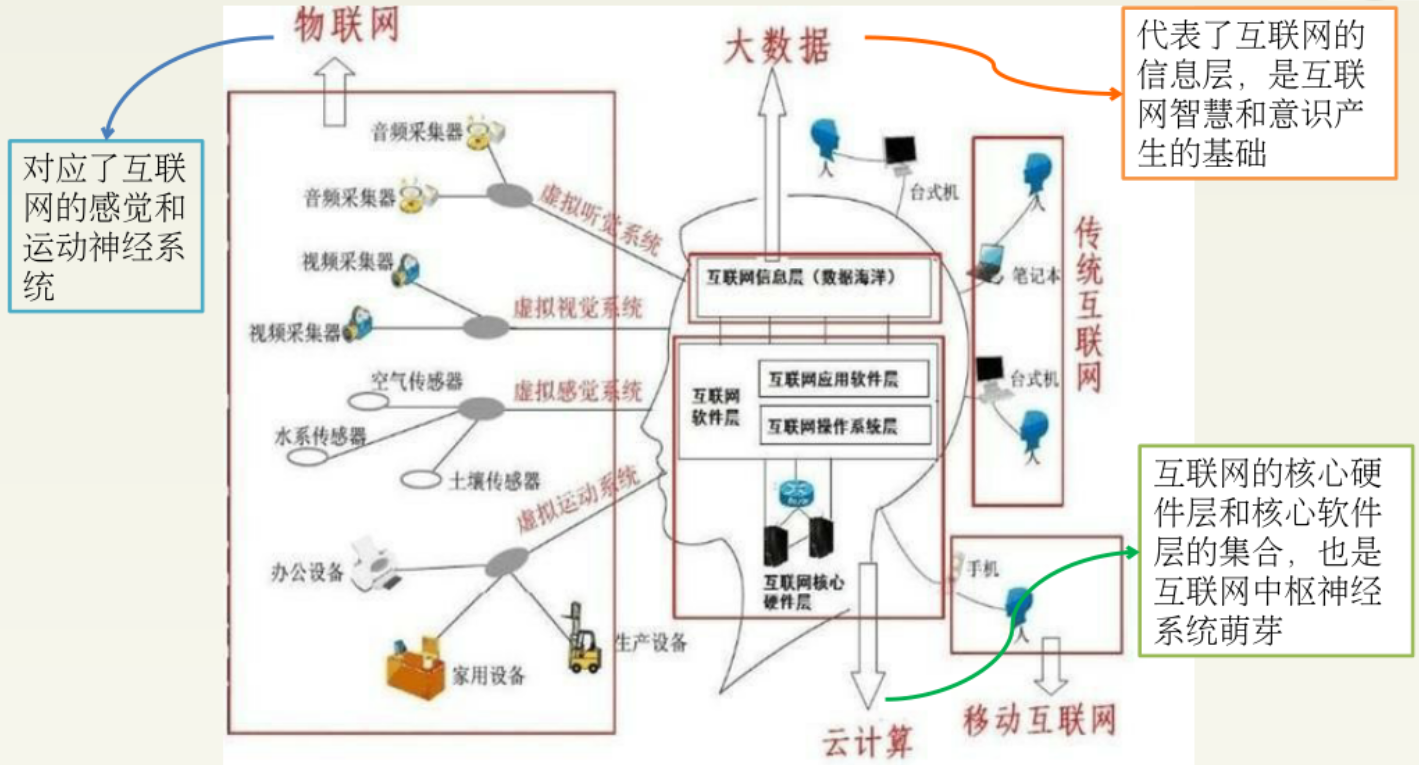
物联网、大数据和云计算三者互为基础,物联网产生大数据,大数据需要云计算。物联网将物品和互联网连接起来,进行信息交换与通信,以实现智能化识别、定位、跟踪、监控和管理的过程中,产生的大量数据,云计算解决万物互联带来的巨大的数据量,所以三者互为基础,又互相促进。
Hadoop
简介
Hadoop框架的核心设计是HDFS和MapReduce。
HDFS为海量数据提供了存储能力。MapReduce为海量数据提供了计算能力。
Hadoop是一个专为离线的大规模数据分析而设计的,而不适合随机读写的在线事务处理。
特性
高可靠性、高效性、高可扩展性、高容错性、成本低、运行在Linux平台、支持多种编程语言。
体系结构
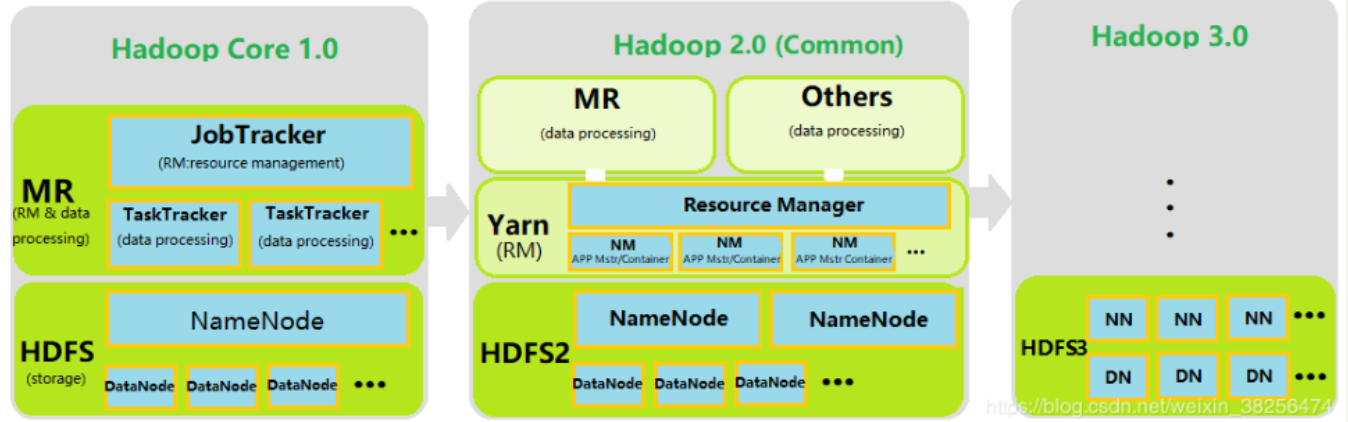
生态系统
Hive: 用于Hadoop的数据仓库,提供了类似于SQL的查询语言。
HBase: 一种分布式、可伸缩的、大数据存储库,支持随机、实时读写。
Spark: 一个开源的数据分析集群计算框架。
ZooKeeper: 一种用于维护配置信息、命名,提供分布式同步等的集中服务。
以上为本门课程学过的东西,以下没有学
Pig: 分析大数据集的平台
Sqoop:可高效传输批量数据的一种工具
Flume:一种用于高效搜集、汇总、移动大量日志数据的服务
Storm:一个分布式的、容错的实时计算系统
Avr:一个数据序列化系统
HDFS
概念
全称为Hadoop分布式文件系统,是2003年10月Google发表的GFS论文的开源实现,为海量数据提供了存储能力。
体系结构
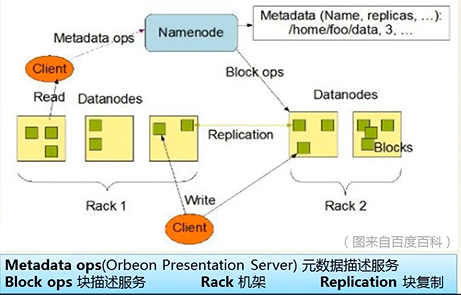
如图为HDFS的系统架构图
其中有一个NameNode和多个DataNodes, Client需要跟NameNode获取元数据信息,需要向各个DataNode进行读写。
Client主要功能
- 上传文件时将文件切分为Block,在文件下载时将文件合并。
- 在上传下载文件时,与NameNode交互获取文件元数据。
- 在上传下载文件时,与DataNode交互读写数据。
NameNode(NN)主要功能
主要功能是提供名称查询服务,用来保存文件的metadata信息,包括:
- 管理文件系统的命名空间(维护者文件系统树与树内所有文件与目录)
- 管理元数据:文件的位置、所有者、权限、数据块信息
- 管理Block副本策略:多少副本,默认三个
- 处理客户端读写请求,为DataNode分配任务
DataNode(DN)主要功能
主要功能保存Block
- 作为一个个的Slave工作节点(可大规模扩展)
- 存储Block与数据校验,执行客户端读写请求
- 通过心跳向NameNode汇报运行状态与Block列表信息
- 集群启动时,DataNode向NameNode提供Block列表信息
存储原理
Block数据块
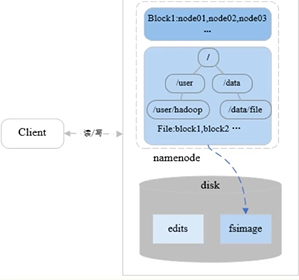
- Block是HDFS的最小存储单元
- 文件写入HDFS会被切分为若干个Block
- Block大小固定,默认为128MB,可自定义
- 若一个Block的大小小于给定值,物理存储上也不会占用整个块空间
- 默认情况每个Block有三个副本
如何设置Block大小
- 目标:最小化寻址开销,降到1%以下
- 默认大小:128M
- 块太小:寻址时间占比过高
- 块太大:Map任务少,作业执行速度变慢
Block和元数据分开存储
Block存储于DataNode,元数据存储于NameNode
Block多副本
- 以DataNode节点为备份对象
- 机架感知:将副本存储到不同的机架上,实现数据的高容错
- 副本均匀分布:提高访问带宽和读取性能,实现负载均衡
Block副本存放机制
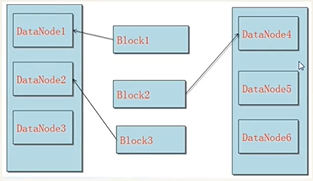
- 第一个副本由客户端上传到DataNode上
- 第二个副本将由第一个DataNode发送到与第一个节点不同机架的节点上
- 第三个副本由第二个副本的的DataNode发送到与第一个副本的机架相同的其他节点
原因:为了防止数据阻塞,防止单机并发量过高。
PS: Block块大小与副本数都是在Client端上传文件时便可设置。Block大小在上传后便不可变更,副本数可以变更。
数据读写
文件写入
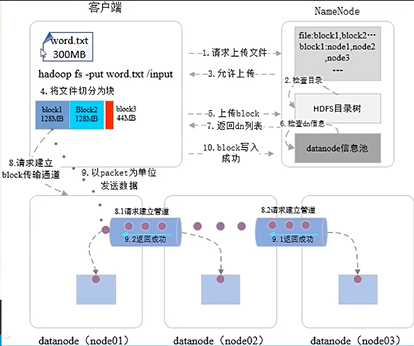
- 向NameNode请求上传文件
- NameNode检查目录是否已存在文件
- 返回是否允许上传的结果
- 客户端将文件切分为块
- 客户端向NameNode提出待上传的Block信息列表
- NameNode检查各个DataNode
- NameNode向客户端返回可写入的DataNode列表
- 客户端连接相应的DataNode
- 客户端以packet为单位发送数据
- Block写入成功通知NameNode记录元数据
文件读取
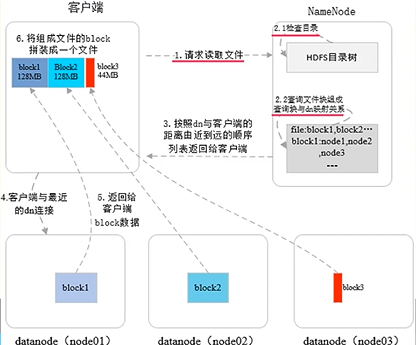
- 向NameNode请求读取文件
- NameNode查找目录树,查找Block与DataNode的对应关系
- 按照DataNode与客户端的距离由近到远的顺序返回给客户端
- 客户端选择最近的DataNode连接
- 被连接的DataNode返回给客户端Block数据
- 将各个Block重新组装回原文件
常用Shell命令
HDFS基本操作MapReduce
体系结构
主要由四个部分组成,分别是:Client、JobTracker、TaskTracker以及Task。
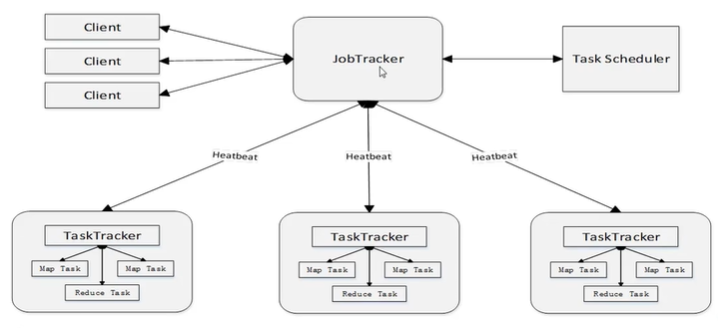
Client
用户编写的MapReduce程序通过Client提交到JobTracker端
JobTracker
JobTracker负责资源监控和作业调度;
JobTracker监控所有TaskTracker与Job的健康状况,一旦发现失败,就将相应的任务转移到其他节点;
JobTracker会跟踪任务的执行进度、资源的使用量等信息,并将这些信息告诉任务调度器(TaskScheduler),而调度器会在资源出现空闲时,选择合适的任务去使用这些资源。
TaskTracker
TaskTracker会周期性地通过“心跳”将本节点上的资源的使用情况和任务的运行进度汇报给JobTracker,同时接收JobTracker发送过来的命令并执行相应的操作(如启动新任务,杀死任务等);
TaskTracker使用“slot”等量划分本节点上的资源量(CPU、内存等)。一个Task获取到一个slot后才有机会运行,而Hadoop调度器的作用就是将各个TaskTracker上的空闲slot分配给Task使用。slot 分为Mapslot 和Reduce slot 两种,分别供MapTask 和Reduce Task 使用。
Task
Task分为Map Task 和Reduce Task 两种,均由TaskTracker 启动。
原理
工作流程
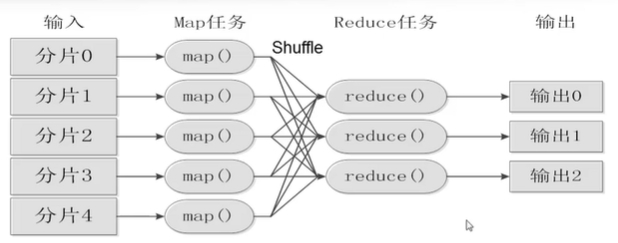
- 不同的map任务之间不会进行通信
- 不同的reduce任务之间不会发生信息交换
- 用户不能显式地从一台机器向另一台机器发送消息
- 所有数据交换都是通过MapReduce框架自身去实现的
以WordCount为例
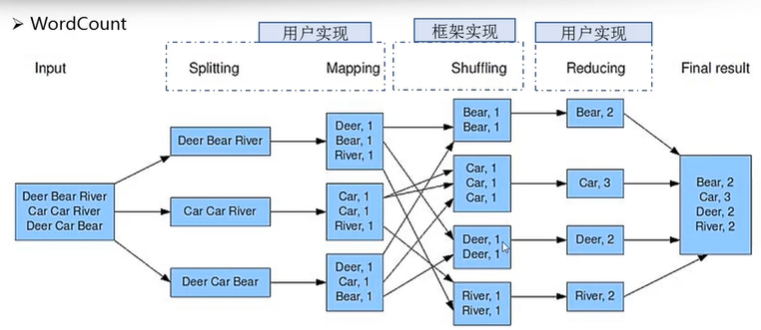
- 我们将任务划分为三份,启动三个Map任务
- 数据将被Map后将被重构分布汇总成四份,每一份对应一个Reduce
- Map将数据转换为键值对,Reduce将键值对合并
在整个分布式集群中的过程如下
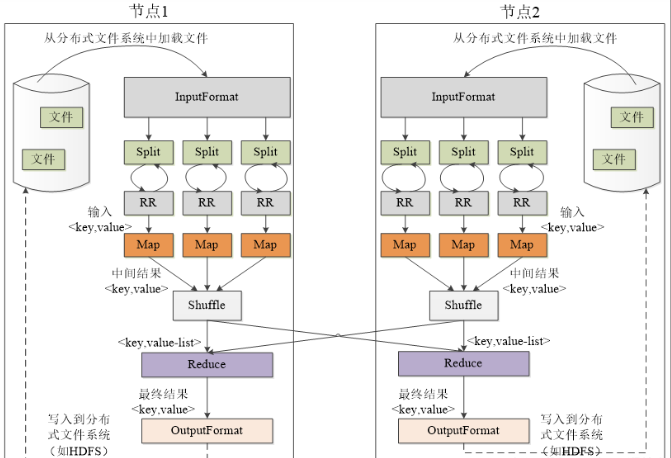
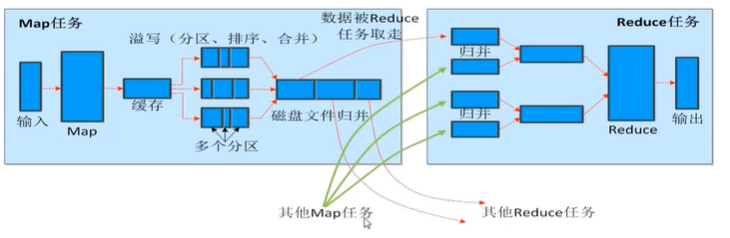
shuffle过程
HBase
概念
HBase是一个高性能、高可靠、面向列的、可伸缩的分布式数据库,是谷歌BigTable的开源实现,主要用来存储非结构化与半结构化的松散数据。
与传统数据库的对比

数据模型
表:HBase采用表来组织数据,表由行和列组成,列可以划分为若干个列族
行:每个HBase表由若干行组成,每个行由行键(RowKey)来标识
列族:一个HBase表被分组为许多列族(ColumnFamily)的集合,它是基本的访问控制单元
列限定符:列族里的数据通过列限定符(或列)来定位
单元格:在HBase表中,通过行、列族或列限定符确定一个”单元格“(Cell),单元格中存储的数据没有数据类型,总被视为字节数组
时间戳:每个单元格都保存着同一份数据的多个版本,这些版本采用时间戳进行索引
PS: 在HBase中,需要通过行键、列族、列限定符、时间戳来确定一个”单元格“(Cell),因此,可以视为一个”四维坐标“,即[行键, 列族, 列限定符, 时间戳]。
HBase按列族进行物理存储
实现原理
HBase的实现主要由三个功能组件
- 库函数:链接到每个客户端
- 一个Master主服务器
- 许多Region服务器
主服务器Master:负责管理和维护HBase表的分区信息,维护Region服务器列表,分配Region,负载均衡;
Region服务器:负责存储和维护分配给自己的Region,处理来自客户端的读写请求;
客户端并不是直接从Master主服务器上读取数据,而是在获得了Region的存储位置信息后,直接从Region服务器上读取数据;
客户端并不依赖Master,而是通过ZooKeeper来获取Region位置信息,大多数客户端甚至从来不和Master通信,这种设计使Master负载很小
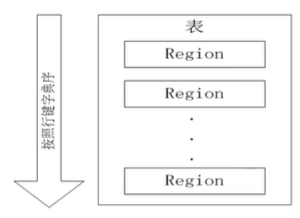
Region
- 分布式存储和负载的最小单元
- 系统将表水平(按行划分为多个Region,每个Region保存表的一段连续数据
- 默认每张表开始只有一个Region,随着数据不断写入,Region不断增大,当Region大小超过阈值时,当前的Region会分裂成两个子Region。
Region拆分
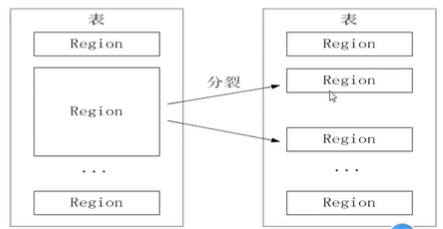
- 开始只有一个Region后来不断分裂
- Region拆分非常快,接近瞬间,因为拆分之后Region读取的仍然是原存储文件,直到”合并“过程才把存储文件异步地写入到独立的文件之后才会读取新文件。
常用shell命令
HBase基本操作Hive
概念
数据仓库是一个面向主题的,集成的,相对稳定的,反应历史变化的数据集合,用于支持管理决策。
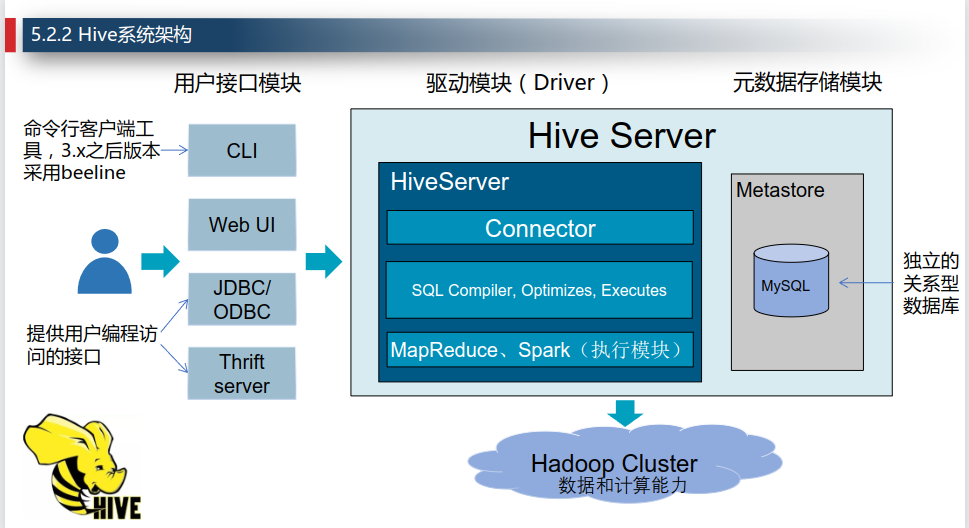
Hive是一个构建于Hadoop顶层的数据仓库工具,支持大规模数据存储,分析,具有良好的可扩展性。
它依赖HDFS存储数据,依赖MapReduce处理数据,定义了类似SQL的查询语言HQL,HQL将转化为MapReduce任务执行。
系统架构
-
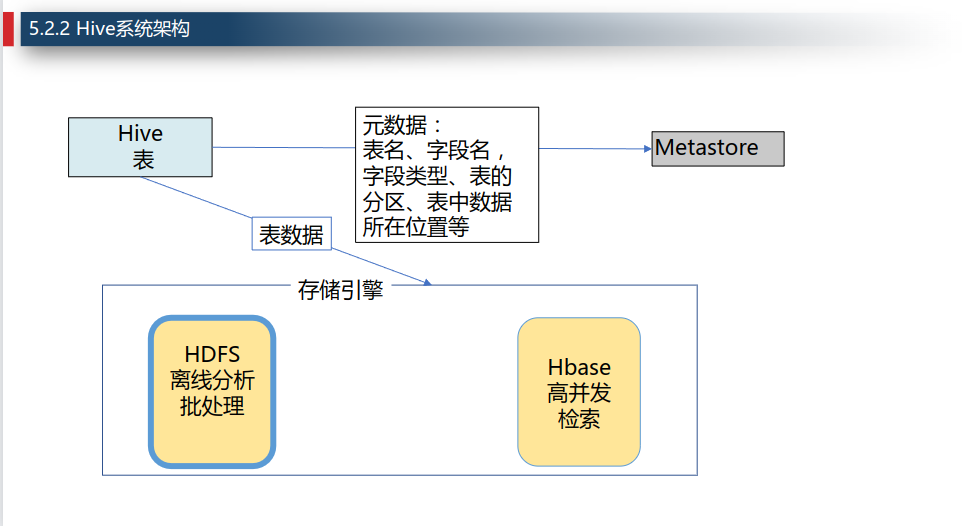
Metastore,存储元数据的角色。Hive将元数据存储在传统的关系型数据库(mysql、derby)中。
-
Hive中的元数据包括:表的名字、表的数据所在的HDFS目录、数据在目录中的分布规则、以及其他表属性。
-
正如Oracle使用的SQL方言是PL/SQL,Hive所使用的SQL方言是HQL。
-
Hive将HQL语句转换成分布式的MapReduce计算任务。
-
Hive计算引擎可以是Apache MapReduce或者Apache Spark。
工作原理
Join原理
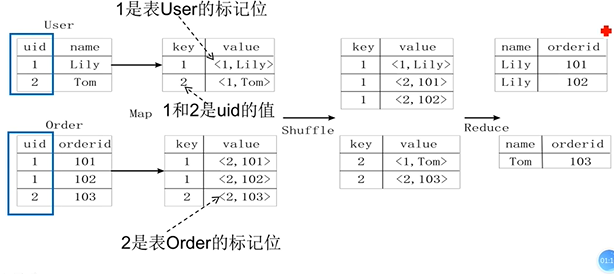
对于如下SQL语句
1 | SELECT name, orderid |
转换得到的MapReduce任务如下
GroupBy原理
计算不同的rank和level的组合值分别有几条记录,即存在一个group by操作,对应SQL语句如下,
1 | SELECT rank, level, count(*) as value |
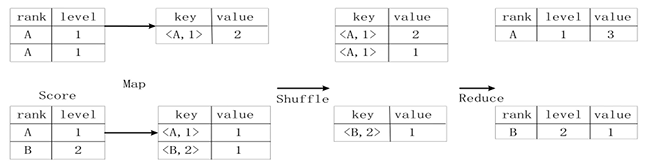
首先对输入进行split得到不同的几个Map任务,然后Map的结果是kv形式,其中key是<rank, level>二元组,value为这个Map任务中的出现的次数(如图已经预合并了,也可以不合并)。
然后通过shuffle将key相同的归为一类,最后Reduce出结果。
内部表与外部表
表
-
表是数据管理和存储的基本对象,由元数据和表数据组成
-
元数据保存在MetaStore中
-
表数据保存在存储引擎中,如HDFS
Hive+HDFS
表数据保存在HDFS,每个表对应一个目录,目录名就是表名
每个数据库对应一个目录,目录名等于数据库名.db
表数据是目录内的文件
表目录在数据库目录下
表目录下,数据可以按照分区和分桶的方式分布
内部表/托管表
-
内部表与关系数据库中的Table在概念上类似;
-
每个Table在Hive中都有一个相应的目录存储数据;
所有的Table数据(不包括External Table)都保存在这个目录中; -
内部表的创建过程和数据加载过程,可以分别独立完成,也可以在同一个语句中完成,在加载数据的过程中,数据会被移动到数据仓库目录中;之后对数据访问将会直接在数据仓库目录中完成。
-
删除表时,元数据与数据都会被删除。
外部表
-
外部表指向已经在HDFS中存在的数据。
-
它和内部表在元数据的组织上是相同的,而实际数据的存储则有较大的差异。
-
外部表只有一个过程,创建表和加载数据同时完成(CREATE EXTERNAL TABLE …… LOCATION),实际数据是存储在LOCATION后面指定的HDFS路径中,并不会移动到数据仓库目录中。
-
删除表时,仅删除该链接,不删除数据。
分区与分桶
分区
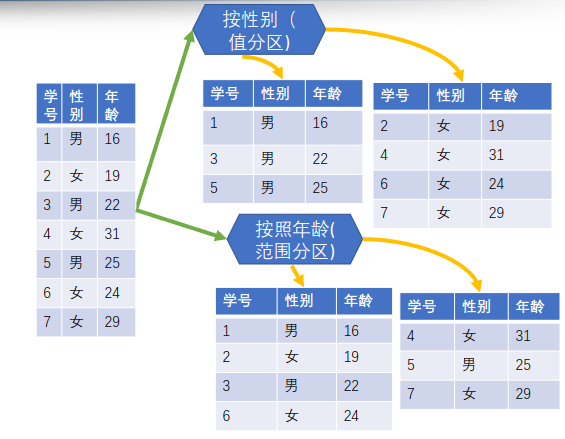
-
含义:通过特定条件(相等或大于小于)将表的数据分发到分区目录中,或者将分区中的数据分发到子分区目录中。
-
作用:减少不必要的全表扫描,提升查询效率,如Select … Where
分桶
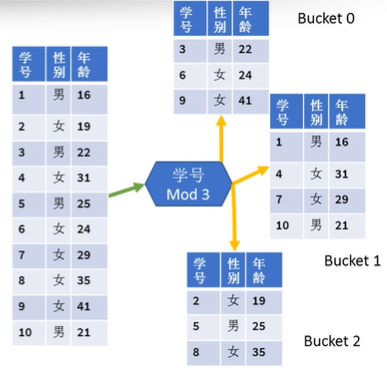
-
含义:通过分桶键哈希取模(key hashcode % N)的方式,将表或分区中的数据随机、均匀地分发到N各桶中,桶数N一般为质数,桶编号为0,1,…,N-1
-
作用:提高取样效率:从桶中直接抽取数据
-
提高Join查询效率:不用全表遍历。可以只和对应地桶进行join
-
分桶操作使得如group by以及特定场景下的join能够在一个stage中完成,避免了shuffle过程,减少了shuffle数据量
-
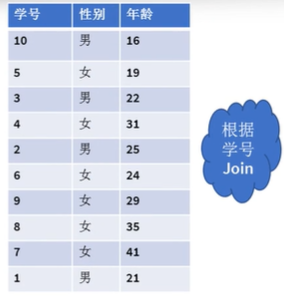
如图,根据学号join,如果未分桶,则需要全表扫描10*10=100次

如图,若已分桶,则需要扫描次数为3 * 3 + 4 * 4 + 3 * 3 =34次
分区与分桶的区别与联系
分区
数据表可以按照某个字段的值划分分区
-
每个分区是一个目录
-
分区的数量不固定
-
分区下可再有分区或桶
分桶
数据可以根据桶的方式将不同数据放入不同的桶中
-
每个桶是一个文件
-
建表时指定桶个数
-
桶内可排序
-
数据按照某个字段的值Hash后放入某个桶中
分区分桶
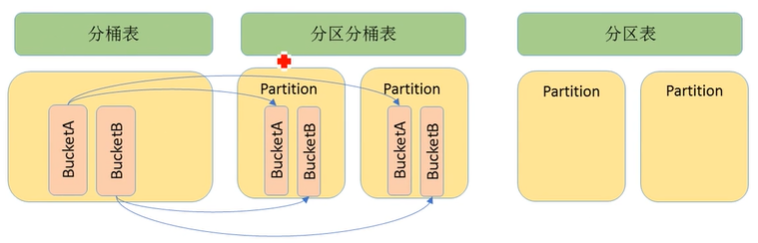
如图,既可以对普通表只分区,也可以对普通表只分桶,还可以对普通表先分区,对每个分区再分桶。
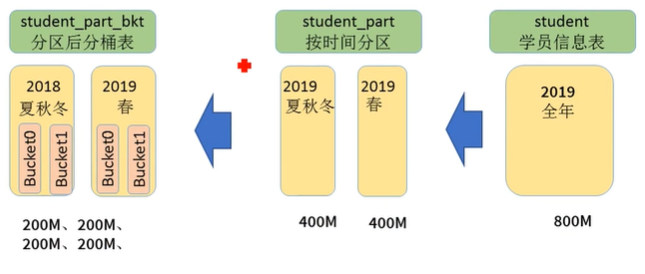
桶文件的大小应当控制在100~200MB之间(ORC表压缩后)
如图,可以对普通的student表按时间分区成400M,400M,再通过分桶分成四个200M,实现文件均衡。
分桶的存储
-
非分区表的分桶:由若干同名文件组成
-
分区表分桶:
-
由分区目录下若干同名文件组成
-
由各个分区下桶文件组成
-
-
事务表多版本和分桶:
-
桶文件由Delta目录Base目录下的同名文件组成
-
桶由桶文件组成
-
文件格式
Text表
-
系统默认的表类型,无压缩,按行存储,仅支持批量insert
-
分析查询的性能较低,主要用于导入原始文本数据时建立过渡表
ORC表
-
优化的列式存储,轻量级索引,压缩比高,仅支持批量insert
-
Hive计算的主要表类型,主要用于数据仓库的离线分析,通常由Text表生成
ORC事务表
-
由ORC表衍生而来,集成了ORC表的所有特性,支持完整CURD(单条和批量的insert,update,delete,merge)以及事务操作
-
多版本文件存储,定期做版本合并,10~20%的性能损失
简单编程
Hive简单应用Spark
特点
运行速度快、容易使用、通用性、运行模式多样
与Hadoop的关系
Hadoop更多是作为分布式数据基础设施,通过HDFS为海量数据提供了的存储能力,还提供了MapReduce作为计算引擎为海量数据提供了数据分析与计算能力。
Spark则专门作为MapReduce的替代,作为分布式的计算引擎,它并不会进行分布式数据的存储,还是要依赖HDFS。
生态系统
传统大数据生态
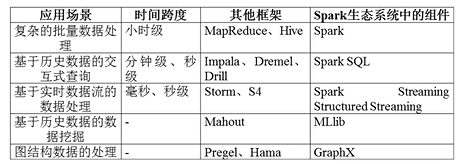
实际应用中,大数据处理主要包括以下三个类型:
-
复杂的批量数据处理:通常时间跨度再数十分钟到数小时之间
- 如MapReduce
-
基于历史数据的交互式查询:通常时间跨度再数十秒到数分钟之间
- 如Hive,Impala
-
基于实时数据流的数据处理:通常时间跨度在数百毫秒到数秒之间
- 如Storm, Flink
当同时存在上述三种场景,就需要同时部署三种不同软件。就会遇到一些问题,如难以共享数据,具有较高的使用成本,难以进行统一资源协调与分配。
Spark生态
Spark也是一个完整的生态系统,如下图所示
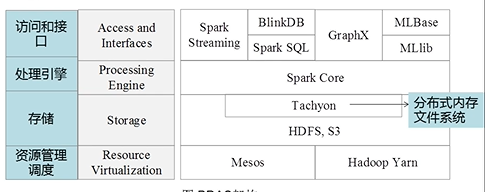
Spark的一些基本概念
RDD:是 Resillient Distributed Dataset (弹性分布式数据集)的简称,是分布式内存的一个抽象概念,提供了一个高度受限的共享内存模型。
DAG:是 Directed Acyclic Graph (有向无环图)的简称,反映了RDD之间的依赖关系。
Executor:是运行在工作节点(WorkerNode)的一个进程,负责运行Task
Application:用户编写的Spark应用程序
Task:运行在Executor上的工作单元
Job:一个Job包含了多个RDD及作用于相应RDD上的各种操作
Stage:是Job的基本调度单位,一个Job分成多组Task,每组Task被称为Stage,或者TaskSet。其代表了一组关联的、相互之间没有Shuffle依赖关系的任务组成的数据集
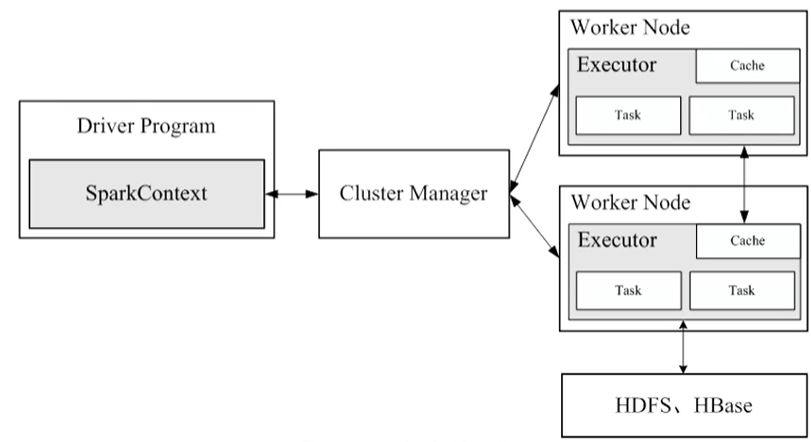
运行架构
Spark运行架构
Spark运行架构包括:
-
集群资源管理器(Cluster Manager)
-
可以使用自带的Mesos
-
也可以使用Hadoop的Yarn
-
-
运行作业任务的工作节点(Worker Node)
-
每个应用的任务控制节点(Driver)
-
每个工作节点负责具体任务的进程(Executor)
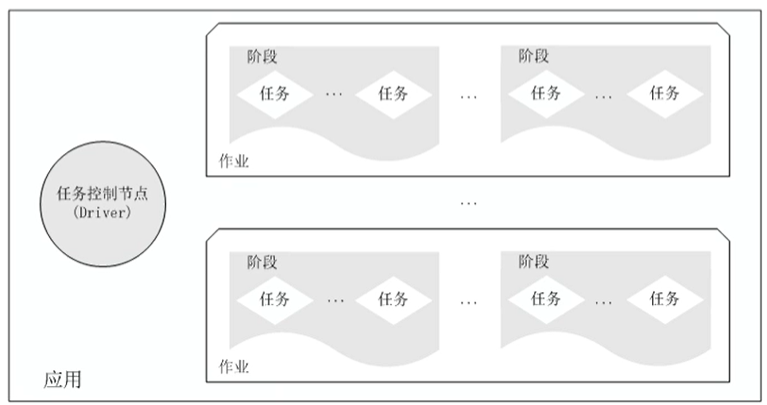
一个应用由一个任务控制节点Driver和若干个作业Job构成,
一个作业由多个节点Stage构成,
一个阶段由多个没有Shuffle关系的任务Task组成
当执行一个应用时,
-
Driver向集群资源管理器申请资源,
-
启动Executor
-
向Executor发送应用程序代码和文件
-
在Executor上执行任务
-
执行结果返回给Driver或者写道HDFS或者其他数据库中
RDD工作原理
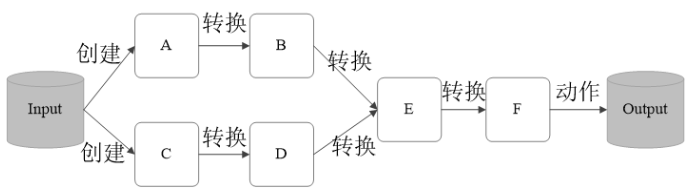
- RDD通过读入外部数据源而创建
- RDD通过一系列的转换 (Transformation) 操作,每次都会产生新的RDD供下一个转换操作使用
- 最后一个RDD通过动作 (Action) 操作进行转换,并输出到外部数据源
操作类型
- 转换(Transformation)
- 动作(Action)
宽依赖与窄依赖
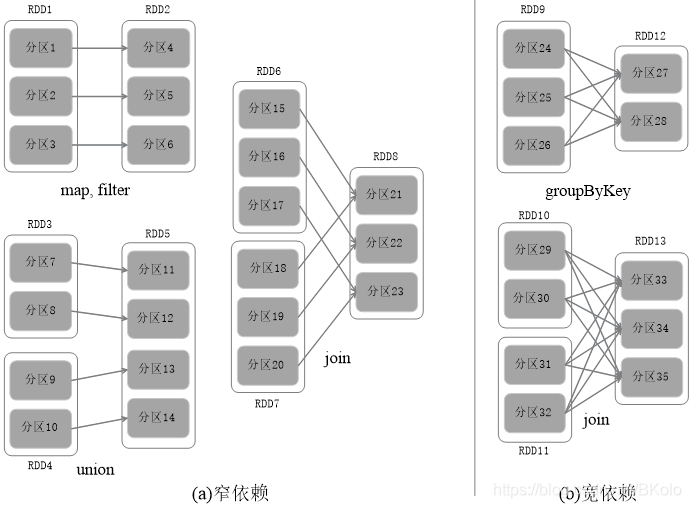
- 窄依赖表现为一个父RDD分区对应一个子RDD分区,或多父RDD分区对应一个子RDD分区
- 宽依赖则表现为存在一个父RDD的一个分区对应一个子RDD的多个分区
SparkSQL工作原理
Spark MLlib基本原理
一些概念
DataFrame
使用SparkSQL中的DataFrame作为数据集,可以容纳各种数据类型。较之RDD,DataFrame包含了schema信息,更加类似传统数据库中的二维表。
它被ML Pipeline用来存储源数据。
Transformer
转换器,是一种可以将一个DataFrame转换为另一个DataFrame的算法。如一个模型就是一个Transformer。它可以把一个不包含预测标签的测试集的DataFrame打上标签,转化成另一个包含预测标签的DataFrame。
大致方法原型为DataFrame Transformer.transform(DataFrame)
Estimator
估计器或评估器,它是某种学习算法,或在训练数据上的训练方法的概念抽象。在Pipeline里通常是被用来操作DataFrame数据并生成一个Transformer。
从技术上将,估计器有一个抽象方法fit()需要被具体算法去实现,它接收一个DataFrame并产生一个转换器。
大致方法原型如下Transformer Estimator.fit(DataFrame)。
即通过Estimator对某个数据集进行fit操作后得到Transformer。
Parameter
参数,参数被用来设置Transformer或者Estimator的参数。现在所有转换器和估计器可共享用于指定参数的公共API。
PipeLine
流水线或管道,流水线将多个工作流阶段(转换器和估计器)连接在一起,形成机器学习的工作流,并获得结果输出。
注意流水线本身也是一个Estimator,在执行完fit操作后,产生一个PipelineModel,它也是一个Transformer。
 wechat
wechat- alipay

